CAP Twelve Years Later: How the "Rules" Have Changed
Perspectives on the CAP Theorem
Tuesday, December 15, 2015
Wednesday, December 9, 2015
Some links
Parallel data structures
https://www.addthis.com/blog/2013/04/25/the-secret-life-of-concurrent-data-structures
Algorithm Design: Parallel and Sequential
http://www.parallel-algorithms-book.com/
Types, Semantics and Verification (replace 13 with 05~15)
https://www.cs.uoregon.edu/research/summerschool/summer13/curriculum.html
ScalaSTM
http://nbronson.github.io/scala-stm/
Operational semantics of Scala
http://infoscience.epfl.ch/record/85784/files/EPFL_TH3556.pdf
Denotational design and FRP
http://programmers.stackexchange.com/questions/183867/applying-denotational-semantics-to-design-of-programs
https://www.addthis.com/blog/2013/04/25/the-secret-life-of-concurrent-data-structures
Algorithm Design: Parallel and Sequential
http://www.parallel-algorithms-book.com/
Types, Semantics and Verification (replace 13 with 05~15)
https://www.cs.uoregon.edu/research/summerschool/summer13/curriculum.html
ScalaSTM
http://nbronson.github.io/scala-stm/
Operational semantics of Scala
http://infoscience.epfl.ch/record/85784/files/EPFL_TH3556.pdf
Denotational design and FRP
http://programmers.stackexchange.com/questions/183867/applying-denotational-semantics-to-design-of-programs
Tuesday, December 8, 2015
Generate thumbnails for videos
Output a single frame from the video into an image file:
Output one image every second, named out1.png, out2.png, out3.png, etc.
Output one image every ten minutes:
2. wiki: Create a thumbnail image every X seconds of the video
3. How to Generate PNG Screenshots Using FFMPEG
ffmpeg -i input.flv -ss 00:00:14.435 -vframes 1 out.pngThis example will seek to the position of 0h:0m:14sec:435msec and output one frame (-vframes 1) from that position into a PNG file.
Output one image every second, named out1.png, out2.png, out3.png, etc.
ffmpeg -i input.flv -vf fps=1 out%d.pngOutput one image every minute, named img001.jpg, img002.jpg, img003.jpg, etc.
ffmpeg -i myvideo.avi -vf fps=1/60 img%03d.jpg -s 250x200The
%03d dictates that the ordinal number of each output image will be formatted using 3 digits. The -s option resizes the output images to 250 x 200.Output one image every ten minutes:
ffmpeg -i test.flv -vf fps=1/600 thumb%04d.bmpOutput one image for every I-frame:
ffmpeg -i input.flv -vf "select='eq(pict_type,PICT_TYPE_I)'" -vsync vfr thumb%04d.png
References
1. https://www.ffmpeg.org/ffmpeg.html2. wiki: Create a thumbnail image every X seconds of the video
3. How to Generate PNG Screenshots Using FFMPEG
Tuesday, December 1, 2015
Scala's parallel collections
The design ideas behind Scala's parallel collections:
http://infoscience.epfl.ch/record/150220/files/pc.pdf
http://infoscience.epfl.ch/record/150220/files/pc.pdf
Sunday, November 29, 2015
A quick note on design patterns
This post is a digest of multiple sources in the reference list. Figures and texts are freely borrowed from the references. Modifications are made only when necessary.
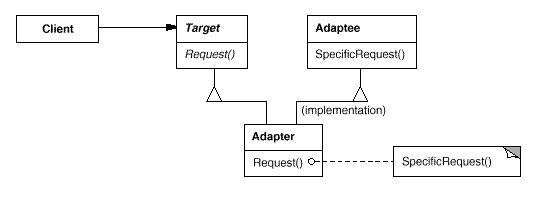
Adapter. Convert the interface of a class into another interface that the clients expect. Adapter lets classes work together that could not otherwise because of incompatible interfaces. Basically, this is saying that we need a way to create a new interface for an object that does the right stuff but has the wrong interface.
 In the above figure, the Adapter adapts the interface of an Adaptee to match that of Target, which is the class the Adapter derives from. This allows the Client to use the Adaptee as if it were a Target.
In the above figure, the Adapter adapts the interface of an Adaptee to match that of Target, which is the class the Adapter derives from. This allows the Client to use the Adaptee as if it were a Target.
Facade. Provide a unified interface to a set of interfaces in a complex system. Basically, this is saying that we need to interact the system in a particular way (such as using a 3D drawing program in a 2D way). Facade defines a higher-level interface that makes the system easier to use.

Note that most of the work in a Facade still needs to be done by the underlying system. The Facade only provides a collection of easier-to-understand methods. These methods use the underlying system to implement the newly defined functions.
Adapter v.s Facade Both Adapter and Facade are wrapper patterns. However, there are at least two major differences between them: a) In most applications, Facade hides multiple classes behind it whereas Adapter only hides one. b) The motivation of Facade is to simplify an interface, while Adapter converts an interface into another without emphasizing on simplification.
Strategy. Define a family of algorithms, encapsulate each one, and make them interchangeable in the context. Being able to plug in different implementations for an operation is a common requirement in many situations. For example, being able to use different encryption and decryption algorithms, or different algorithms for breaking a stream of text into lines. Strategy pattern lets the implementations be selected as required, or vary independently from clients that use it.

In the above figure, Strategy specifies how the different algorithms are used. ConcreteStrategies implement these different algorithms. Context uses a specific ConcreteStrategy with a reference of type Strategy. Strategy and Context interact to implement the chosen algorithm. The Context forwards requests from its client to Strategy, and Strategy may query Context for information.
Bridge. Decouple an abstraction from its implementation so that the two can vary independently. "Implementations" here means the objects that the abstract class and its derivations use to implement themselves, not the derivations of the abstract class, which are called concrete classes.

In the above figure, Abstraction defines the interface for the objects being implemented. Implementation defines the interface for the specific implementation classes. Classes derived from Abstraction use classes derived from Implementation without knowing which particular concrete implementation is in use.
Abstract Factory. Provide an interface for creating families of related or dependent objects without specifying their concrete classes. This pattern isolates the rules of which objects to use from the logic of how to use these objects. The term "abstract" suggests that you define an abstract class that specifies which objects are to be made, and then implement one concrete class for each family.

Flyweights. Allow fine-grained objects to be shared, avoiding the expense of multiple instances. In many applications, a large number of small objects may be created, referenced briefly and then discarded at runtime. If these objects are essentially the same, and particularly if they share state information and are immutable, then it is beneficial to offer a mechanism to allow these objects to be easily shared and reused.

For example, Java strings are immutable objects that are treated as flyweights. Hence, one string “John” is shared between all the references to that string by the JVM (see also: string interning).
Proxy. Make use of a surrogate or placeholder for another object allowing controlled access to that object or for that object to be created lazily. Utilizing the Proxy pattern allows standardized access to the service ensuring that all client code accesses the service in the appropriate manner.

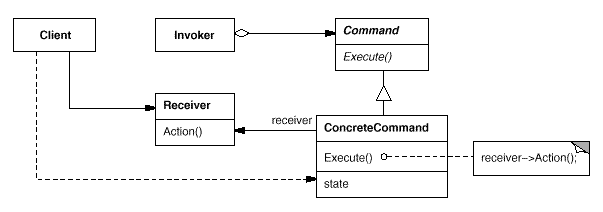
Command. Encapsulates behavior into an object so that it can be selected, sequenced, queued, done and undone, submitted to clients for execution (locally or remotely) and otherwise manipulated.
 In the above diagram, the Command declares an interface for executing an operation. The ConcreteCommand defines a binding between a Receiver object and an action. The Client creates a ConcreteCommand object and sets its receiver, which should know how to perform an action associated with a request. Commands are executed by invoking the corresponding operations on the Receiver object.
In the above diagram, the Command declares an interface for executing an operation. The ConcreteCommand defines a binding between a Receiver object and an action. The Client creates a ConcreteCommand object and sets its receiver, which should know how to perform an action associated with a request. Commands are executed by invoking the corresponding operations on the Receiver object.
Mediator. Define an object that represents a common communication mechanism, that allows a set of objects to interact, without those objects needing to maintain links to each other. It therefore promotes a loosely coupled, but high cohesive communication infrastructure without each object need to maintain a reference to all the other objects.
 Object oriented design encourages the distribution of behaviour among objects. However, this can lead to a multiplicity of links between objects. In the worst case every object needs to know about/link to every other object. This can be a problem for maintenance and for the reusability of the individual classes. These problems can be overcome by using a mediator object. In this scheme, other objects are connected together via a central mediator object in a star like structure. The mediator is then responsible for controlling and coordinating the interactions of the group of objects.
Object oriented design encourages the distribution of behaviour among objects. However, this can lead to a multiplicity of links between objects. In the worst case every object needs to know about/link to every other object. This can be a problem for maintenance and for the reusability of the individual classes. These problems can be overcome by using a mediator object. In this scheme, other objects are connected together via a central mediator object in a star like structure. The mediator is then responsible for controlling and coordinating the interactions of the group of objects.
Mediator vs. Proxy Both serves as an intermediate object between a client and a service. However, Proxy is a one-to-one mapping and thus the client has to maintain links to each of the proxies it is working with.
Mediator vs. Facade Both offer an abstraction over complex interactions. However, Mediator is multi-directional while Facade is unidirectional.
2. Scala Design Patterns, 2013th ed. by John Hunt.
3. Design Patterns, 1st ed. by the GoF.
4. http://www.cs.mcgill.ca/~hv/classes/CS400/01.hchen/doc/
5. https://javaobsession.wordpress.com/design-patterns/
Adapter. Convert the interface of a class into another interface that the clients expect. Adapter lets classes work together that could not otherwise because of incompatible interfaces. Basically, this is saying that we need a way to create a new interface for an object that does the right stuff but has the wrong interface.
Facade. Provide a unified interface to a set of interfaces in a complex system. Basically, this is saying that we need to interact the system in a particular way (such as using a 3D drawing program in a 2D way). Facade defines a higher-level interface that makes the system easier to use.

Adapter v.s Facade Both Adapter and Facade are wrapper patterns. However, there are at least two major differences between them: a) In most applications, Facade hides multiple classes behind it whereas Adapter only hides one. b) The motivation of Facade is to simplify an interface, while Adapter converts an interface into another without emphasizing on simplification.
Strategy. Define a family of algorithms, encapsulate each one, and make them interchangeable in the context. Being able to plug in different implementations for an operation is a common requirement in many situations. For example, being able to use different encryption and decryption algorithms, or different algorithms for breaking a stream of text into lines. Strategy pattern lets the implementations be selected as required, or vary independently from clients that use it.
Bridge. Decouple an abstraction from its implementation so that the two can vary independently. "Implementations" here means the objects that the abstract class and its derivations use to implement themselves, not the derivations of the abstract class, which are called concrete classes.
Abstract Factory. Provide an interface for creating families of related or dependent objects without specifying their concrete classes. This pattern isolates the rules of which objects to use from the logic of how to use these objects. The term "abstract" suggests that you define an abstract class that specifies which objects are to be made, and then implement one concrete class for each family.


Proxy. Make use of a surrogate or placeholder for another object allowing controlled access to that object or for that object to be created lazily. Utilizing the Proxy pattern allows standardized access to the service ensuring that all client code accesses the service in the appropriate manner.
Command. Encapsulates behavior into an object so that it can be selected, sequenced, queued, done and undone, submitted to clients for execution (locally or remotely) and otherwise manipulated.
Mediator. Define an object that represents a common communication mechanism, that allows a set of objects to interact, without those objects needing to maintain links to each other. It therefore promotes a loosely coupled, but high cohesive communication infrastructure without each object need to maintain a reference to all the other objects.
Mediator vs. Proxy Both serves as an intermediate object between a client and a service. However, Proxy is a one-to-one mapping and thus the client has to maintain links to each of the proxies it is working with.
Mediator vs. Facade Both offer an abstraction over complex interactions. However, Mediator is multi-directional while Facade is unidirectional.
References
1. Design Patterns Explained, 2nd ed. by Alan Shalloway and James R. Trott.2. Scala Design Patterns, 2013th ed. by John Hunt.
3. Design Patterns, 1st ed. by the GoF.
4. http://www.cs.mcgill.ca/~hv/classes/CS400/01.hchen/doc/
5. https://javaobsession.wordpress.com/design-patterns/
Tuesday, November 3, 2015
Sunday, October 18, 2015
Windows Sysinternals
https://technet.microsoft.com/en-us/sysinternals/bb842062
The Sysinternals Troubleshooting Utilities have been rolled up into a single Suite of tools. Extremely useful in the command line environment.
The Sysinternals Troubleshooting Utilities have been rolled up into a single Suite of tools. Extremely useful in the command line environment.
Sunday, October 11, 2015
The Z3 SMT solver
Z3 is a Satisfiability Modulo Theories (SMT) solver. It is an automated satisfiability checker for many-typed first-order logic with built-in theories, including support for quantifiers. The currently supported theories are:
- equality over free (aka uninterpreted) function and predicate symbols
- real and integer arithmetic
- bit-vectors and arrays
- tuple/records/enumeration types and algebraic (recursive) data-types.
- If a set of formulas F is satisfiable, Z3 can produce a model for F.
- If a set of formulas contains universal quantifiers, then the model produced by Z3 should be viewed as a potential model, since Z3 is incomplete in this case.
Thursday, August 20, 2015
Type classes in Haskell
The inter-relationships of the type classes in the standard Haskell libraries:

- Solid arrows point from the general to the specific; that is, if there is an arrow from Foo to Bar it means that every Bar is (or should be, or can be made into) a Foo.
- Dotted arrows indicate some other sort of relationship.
- Monad and ArrowApply are equivalent.
- Semigroup, Apply and Comonad are greyed out since they are not actually (yet?) in the standard Haskell libraries.
Sunday, July 26, 2015
How to present a regular paper in 15 minutes
- The purpose of presentation is to impress the potential readers of your paper, not to let them understand your paper in 15 minutes.
- Example organization:
- Motivation (e.g., show a running example)
- Related work and contribution
- Background and overview
- Explain the main approaches/results
- Experimental results (if any)
- Conclusions (e.g., summary and future work)
- Use short and simple sentences on your slides.
- Use charts and diagrams instead of texts whenever possible.
- Each slide should have a clear purpose. Remove all slides likely to confuse the audience.
- Present the materials that your audiences (NOT you) are interested in.
- They only care about how helpful your paper is for them.
- Try to skip technical results and use high-level descriptions.
- Most of the audience only care about the key ideas.
- Put the details in backup slides for Q&A.
- Make sure your audience can follow you to the last slide.
- Try to use a running example to explain your approaches.
- Recall definitions, formulas, theorems, etc., upon distant references.
Wednesday, June 24, 2015
Chrome shortcuts
For web developers:
https://developers.google.com/web/tools/chrome-devtools/iterate/inspect-styles/shortcuts
For general users:
https://support.google.com/chrome/answer/157179
It is a shame that I haven't learned of these shortcuts until very recently...
https://developers.google.com/web/tools/chrome-devtools/iterate/inspect-styles/shortcuts
For general users:
https://support.google.com/chrome/answer/157179
It is a shame that I haven't learned of these shortcuts until very recently...
Sunday, May 3, 2015
Sunday, April 19, 2015
Some video links
Verification of Computer Systems with Model Checking
by Ed. M. Clark, at FloC 2014 keynotes
Transducers by Rich Hickey
by Ed. M. Clark, at FloC 2014 keynotes
Transducers by Rich Hickey
Wednesday, April 1, 2015
JavaScript tricks
Duck typing
You can invoke an object's method on another object, as long as the latter has everything the method needs to operate properly. Example:function foo() {
// the last element of arguments is popped
Array.prototype.forEach.pop.bind(arguments)();
// this works as if arguments had a "forEach" method
Array.prototype.forEach.bind(arguments)(function(a){ console.log(a) });
}
Dynamic scoping
The easiest way to archive dynamic scoping in JavaScript is to useeval:
var x = 1;
function g() {
console.log(x);
x = 2;
}
function f() {
// create a new local copy of `g` bound to the current scope
var x = 3;
eval(String(g));
g();
}
f(); // prints 3
console.log(x); // prints 1
Perhaps this is one of the few valid reasons to use eval in JavaScript.
Loose augmentation
Suppose that you have several module files that share aMODULE variable. Then
it is preferable to let organize each module file like
var MODULE = MODULE || {}; // MODULE is always declared due to hoisting
(function() {
var private_var; // only accessible to myFunction
MODULE.myFunction = ... // augment the module with a new function
})();
In this way, you can load all of your module files asynchronously without the need to block,
given that the functions defined in the module don't depend on each other.
Call-site memorization
The word memoization refers to function-level caching for repeating values. Suppose we have a function G such that G(f) will compute an expensive function f many times. If f is pure, then we can cache the results of f without modifying G or introducing global variables. Instead of calling G(f) directly, we pass to G a closure of f as follows:var memorize = function(f) {
var cache = {};
return function(x) {
if(!cache.hasOwnProperty(x))
cache[x] = f(x);
return cache[x];
};
};
G(memorize(f));
The use of cache here is totally transparent from the view of G. Note: You may want to use an LRU/LFU cache to avoid running out of memory.
Saturday, March 28, 2015

Tuesday, March 24, 2015
Tricks in solving common programming problems
O(1)-space collision detection
At times, you need to detect for once whether a collision occurs. For example, you may need to enumerate a sequence$$ x_0,\ x_1=f(x_0),\ x_2=f(x_1),\ \dots,\ x_i=f(x_{i-1}),\ \dots $$until either a desired element is found or a cycle is detected. A naive method to detect a cycle requires storing all elements ever enumerated in a hash table. This method however would need to store the entire sequence in the worst case. Instead, you can utilize one of the cycle detection techniques to reduce the space to O(1) at the cost of possibly longer search time.(more to come...)
Quantifier elimination
A theory has quantifier elimination if for every formula f of the theory, there exists another formula f' without quantifiers that is equivalent to it (modulo the theory).
A common technique to show that the validity of a theory is decidable is to show that the theory admits decidable quantifier elimination and then prove the decidability of quantifier-free sentences. This technique is used to show that Presburger arithmetic, i.e. the theory of the additive natural numbers, is decidable.
Note that theories could be decidable yet not admit quantifier elimination. For example, Example: Nullstellensatz in ACF and DCF. On the other hand, whenever a theory in a countable language is decidable, it is possible to extend its language with countably many relations to ensure that it admits quantifier elimination.
A common technique to show that the validity of a theory is decidable is to show that the theory admits decidable quantifier elimination and then prove the decidability of quantifier-free sentences. This technique is used to show that Presburger arithmetic, i.e. the theory of the additive natural numbers, is decidable.
Note that theories could be decidable yet not admit quantifier elimination. For example, Example: Nullstellensatz in ACF and DCF. On the other hand, whenever a theory in a countable language is decidable, it is possible to extend its language with countably many relations to ensure that it admits quantifier elimination.
Sunday, February 22, 2015
Compiling Z3py on Windows
1. git clone Z3.
2. Install Python. (Either 2.x or 3.x is fine.)
- Note that you have to install 64bit/32bit Python runtime on a 64bit/32bit machine; for otherwise the Z3py library would not initialize (would show a "dll not found" message).
3. Install Visual Studio Community if you don't have Vitual Studio installed. Add the command-line tools of VS to your PATH environment variables.
4. Install Windows SDKs for libraries.
5. Setup environment variables in Cygwin for nmake.
- On my computer, I set these two:
LIBPATH="C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\lib" INCLUDE="C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include;C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include"
6. Configure and nmake Z3
- I have to remove BOM in file
z3\src\api\dotnet\Properties\AssemblyInfoto resolve a decoding problem.
Thursday, February 19, 2015
Implementations of MapReduce
Bash
- https://github.com/erikfrey/bashreduce/tree/master
- Author blog: http://blog.last.fm/2009/04/06/mapreduce-bash-script
- I think the script can be further optimized for concurrent applications. There should be more efficient ways than TCP/IP for mappers and reducers to communicate on a single node.
- Multiple choices available. Need more comparison details.
- https://www.npmjs.com/package/mapred
- https://github.com/dominictarr/map-reduce
- https://github.com/chriso/node.io (popular but no longer maintained)
- http://www.mapjs.org (obsolete)
- https://github.com/twitter/scalding
- Use Spark if possible.
Sunday, February 8, 2015
Pitfalls for Scala beginners --- Part 2
Functions vs. methods. A method
m can be converted to a function using m _.
Note that one can't convert the other way around. The two practical differences between functions and methods are 1) Functions cannot be generic. 2) You cannot return from a function. For example,def foo = {
val f = () => { return }
f()
println("hello") // never printed
}
Also, when you use this inside a function body, it refers to the closure where the function literal is evaluated, while this inside a method body refers to the closure where the method is defined.
Monday, February 2, 2015
Add disk space to the root directory on a VM
# Suppose the second disk is /dev/sdb fdisk /dev/sdb ### In the fdisk shell ### # Create a new partition using command 'n' (default options are fine) # Set its type with command 't' as '8e' (for making it 'Linux LVM') # Write and exit shell with command 'w' # Format the partition you require using mkfs command mkfs -t ext4 -c /dev/sdb1 # Now you can mount /dev/sdb1 on a directory. Go on if you want to # merge it into the root logic volume # create LVM & merging it into root, first creating physical volume pvcreate /dev/sdb1 # Look up the name of the root Volume Group using vgdisplay vgdisplay # Add the newly created physical volume into logical volume group vgextend /dev/<vg_name> /dev/sdb1 # extend it (<logical_volume>is usually 'lv_root') lvextend /dev/<vg_name>/<logical_volume> /dev/sdb1 # resize it resize2fs /dev/<vg_name>/<logical_volume> # Done!
Wednesday, January 21, 2015
Regular expressions
http://www.regular-expressions.info/
This website gives incredibly in-depth explanations about regular expressions. Particularly, it elaborates the subtle differences between the regex supports of popular languages and tools, which I found extremely helpful.
This website gives incredibly in-depth explanations about regular expressions. Particularly, it elaborates the subtle differences between the regex supports of popular languages and tools, which I found extremely helpful.
Saturday, January 17, 2015
Pitfalls for Scala beginners --- Part 1
Type erasure. Consider the following code:
Iterated binding. According to section 4.1 of The Scala Language Specification, a value definition
Overridden val. The Scala compiler binds a
Binding vs assignment. In Scala,
Right-associative operators. All operators, including those custom ones, that ends in a ":" would be right-associative in Scala. For example, the List concatenation
Type widening. Suppose you have an implicit conversion from String to Option:
Iterators vs Traversables. Iterators in Scala provide analogues of most of the methods that you find in the Traversable classes. For instance, they all provide a foreach method which executes a given procedure on each element. The biggest differences between iterators and traversables is that iterators has states. An iterator maintain a pointer that is advanced automatically and cannot be rewinded. Hence, you cannot reuse an iterator after invoking foreach on it. See this document for details.

class Box[E](e: E) {
def unbox: E = e
def rebox(e: E): Box[E] = new Box(e)
}
val box1 = new Box(1)
val boxes: Seq[Box[_]] = Seq(box1) // the type info of Int is lost due to "_"
val box2 = boxes.head
box1.rebox(box1.unbox) // ok
box2.rebox(box2.unbox) // compile-time error!
The last line cannot compile because the Scala compiler cannot tell whether the return type of box2.unbox matches the type parameter of box.
One way to solve this problem is to introduce a fresh type parameter for the rebox method,
so that the argument type of rebox and the type parameter of Box are allowed to be different:
class Box[E](e: E) {
def unbox: E = e
def rebox[F](e: F): Box[F] = new Box(e) // use a new type parameter for rebox
}
Capital identifiers. Scala's pattern matching mechanism automatically presumes within patterns that all identifiers with an initial capital letter are constants. Hence, val (a,b) = (1,2) is fine but val (A,b) = (1,2) cannot compile due to undefined A. On the other hand, if you set, say, A = 2 before the matching, then it will compile but instead rise a MatchError exception at runtime.
Iterated binding. According to section 4.1 of The Scala Language Specification, a value definition
val p1,...,pn = e is a shorthand for the sequence of value definitions val p1 = e; ...; val pn = e. Hence, the following code
val next = { var n = 0; () => { n = n + 1; n } }
val p1, p2, p3, p4, p5, p6, p7, p8 = next()
binds $p_i$ to $i$ for each $i$.Overridden val. The Scala compiler binds a
val variable only once. Hence, if a val variable is overridden in a subclass, it will be initialized in that subclass and appear as its default value before that time, even though it is also initialized in the superclass. For example,
trait A {
val foo = 10
println(s"foo in A: $foo")
}
class B extends A {
override val foo = 11
println(s"foo in B: $foo")
}
new B // prints "foo in A: 0", "foo in B: 11"
The point is that access to foo is carried out through an accessor foo() overridden in B. Hence, even though there is a field foo in the superclass, it is effectively hidden from the constructors, and B.foo returns the value set in B after the parent constructors are called.
Note that the same holds for Java: you access fields of the subclass through the overridden method, which gives the default value when the method is called in the constructor of the superclass.Binding vs assignment. In Scala,
val denotes binding and var denotes assignment. When one uses var to declare a variable, the closure is made over its reference instead of its value. Hence, the value of the variable is still mutable after the variable is enclosed. Consider the follows code:val fs = Buffer[() => Unit]()
{// closure I
val a = 1
var b = 2
fs += (() => println(a + " " + b)) // closure II
b = 3
}
val a = 4
fs foreach { f => f() } // print 1 3
Inside closure II, a binds to a value (ie. 1) while b binds to a reference.
As the value of b changes, the new value is visible to all closures that can access b. Hence, one has to use val to capture values in a closure.Right-associative operators. All operators, including those custom ones, that ends in a ":" would be right-associative in Scala. For example, the List concatenation
a ::: b ::: c is translated to method calls c.:::(b).:::(a).
Type widening. Suppose you have an implicit conversion from String to Option:
implicit def StrToOpt(s: String) = Option(s)
val opt1: Option[String] = "a".get() // Ok due to conversion
val opt2: Option[String] = "a".getOrElse("") // Boo! type-mismatch error!
The problem is a result of incomplete tree traversal. The signaturedef getOrElse[B >: A](default: => B): Ballows type widening. Thus, when the compiler realizes that the return type of
getOrElse is not as expected, it tries to generalize the type.
In this case, it tries to identify a supertype of String, which is Serializable, and then gets stuck there.
A solution to this is to use
val opt2: Option[String] = "a".getOrElse[String]("")
Now the return type is forced to be a String, so the compiler finds the implicit without wandering around the type hierarchy.
The lesson: in the presence of type widening/narrowing, the compiler can make the type too general before checking for implicits. Putting explicit type annotation help avoid this problem.Iterators vs Traversables. Iterators in Scala provide analogues of most of the methods that you find in the Traversable classes. For instance, they all provide a foreach method which executes a given procedure on each element. The biggest differences between iterators and traversables is that iterators has states. An iterator maintain a pointer that is advanced automatically and cannot be rewinded. Hence, you cannot reuse an iterator after invoking foreach on it. See this document for details.

Note: Do not confuse Iterator classes with Iterable classes. See this document for all full hierarchy of Scala's collections.
Sunday, January 11, 2015
Inheritance of Objects in Scala
Extending an object in Scala is not allowed due to the singleton semantics of objects. However, at times you may find yourself tempted to do so, e.g., to add some methods to an object. You have two choices to fulfill your requirement:
Refactoring. If possible, try to extract the interesting behaviors of the target object into an abstract trait, so that you can extend a trait instead of an object. This is also the standard solution in OOP textbooks.
Implicit conversion. You can make an object Y look like an extension of object X using implicit modifier:
Refactoring. If possible, try to extract the interesting behaviors of the target object into an abstract trait, so that you can extend a trait instead of an object. This is also the standard solution in OOP textbooks.
Implicit conversion. You can make an object Y look like an extension of object X using implicit modifier:
object X { def a = 1 }
object Y { def b = 2 }
implicit def YToX(y: Y.type) = X
println(Y.a)
In this way, you can call methods on Y that were originally defined for X. Note that Y doesn't actually extend X, so there are still many big differences between this design and OO-inheritance. For example, you cannot override methods from X, you cannot substitute Y for X in your code, etc.
Saturday, January 10, 2015
Basic notions of Lambda calculus
$\alpha$-conversion changes names of bound variables to fresh ones before substitution. $\alpha$-equivalence equates formulas that differ only in the naming of bound variables. Note that we consider two normal forms to be equal if they are $\alpha$-equivalent.
$\beta$-reduction applies a $\lambda$-term to another term: $(\lambda x.\, e)\ e' \mapsto e\ [e'/x]$. Two expressions are $\beta$-equivalent, if they can be $\beta$-reduced into the same expression.
$\eta$-conversion converts between $λx.(f\ x)$ and $f$ whenever $x \not\in FV(f)$. It expresses the ideas that two functions are the same if and only if they give the same result for all arguments. Hence a function and its eta-conversion is $\eta$-equivalent. In FP, we usually use $\eta$-conversion to bound free variables inside an expression, e.g., to convert $e: A\rightarrow B \rightarrow C$ to $\lambda x.\lambda y.e$.
$\eta$-conversion (together with rule $M \equiv N \implies M\ x \equiv N\ x$) yields the Extensional Principle: $M\ x \equiv N\ x \implies M\equiv N$, given that $x\not\in FV(M)\cup FV(N)$. This principle expresses the lambda calculus form of the notion of extensional equality for functions. That is, two functions $f, g: A\rightarrow B$ are indistinguishable iff $f\ x \equiv g\ x$ for all $x:A$.
The term redex, short for reducible expression, refers to subterms that can be reduced by one of the reduction rules. For example, $(λx.M)\ N$ is a beta-redex, and $λx.M\ x$ is an $eta$-redex if $x$ is not free in $M$. The expression to which a redex reduces is called its $reduct$. Using the previous example, the reducts of these expressions are respectively $M[N/x]$ and $M$.
$\beta$-reduction applies a $\lambda$-term to another term: $(\lambda x.\, e)\ e' \mapsto e\ [e'/x]$. Two expressions are $\beta$-equivalent, if they can be $\beta$-reduced into the same expression.
$\eta$-conversion converts between $λx.(f\ x)$ and $f$ whenever $x \not\in FV(f)$. It expresses the ideas that two functions are the same if and only if they give the same result for all arguments. Hence a function and its eta-conversion is $\eta$-equivalent. In FP, we usually use $\eta$-conversion to bound free variables inside an expression, e.g., to convert $e: A\rightarrow B \rightarrow C$ to $\lambda x.\lambda y.e$.
$\eta$-conversion (together with rule $M \equiv N \implies M\ x \equiv N\ x$) yields the Extensional Principle: $M\ x \equiv N\ x \implies M\equiv N$, given that $x\not\in FV(M)\cup FV(N)$. This principle expresses the lambda calculus form of the notion of extensional equality for functions. That is, two functions $f, g: A\rightarrow B$ are indistinguishable iff $f\ x \equiv g\ x$ for all $x:A$.
The term redex, short for reducible expression, refers to subterms that can be reduced by one of the reduction rules. For example, $(λx.M)\ N$ is a beta-redex, and $λx.M\ x$ is an $eta$-redex if $x$ is not free in $M$. The expression to which a redex reduces is called its $reduct$. Using the previous example, the reducts of these expressions are respectively $M[N/x]$ and $M$.
Thursday, January 8, 2015
Spark glossary
Data structures
RDD is a distributed memory abstraction that allows programmers to perform in-memory computations on large clusters while retaining the fault tolerance of data flow models like MapReduce. As a data structure, an RDD is a lazy, read-only, partitioned collection of records created through deterministic transformations (e.g., map, join and group-by) on other RDDs.The lineage of an RDD is the series of transformations used to build it. More vaguely, it also refers to the information needed to derive an RDD from other RDDs. Logging lineages allows an RDD to reconstruct lost partitions without requiring costly checkpointing and rollback.
RDDs vs. DSM. In DSM models, applications read and write to arbitrary locations in a global address space. DSM is a very general abstraction, but this generality makes it harder to implement in an efficient and fault-tolerant manner on commodity clusters. The main difference between RDDs and DSM is that RDDs can only be created (“written”) through bulk transformations, while DSM allows reads and writes to each memory location. This restriction of RDDs allows for more efficient fault tolerance. In particular, RDDs do not need to incur the overhead of checkpointing, as they can be recovered using lineages.
The execution model
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program, called the driver program. A worker node is a node that can run application code in the cluster. Each worker node in the cluster can have several executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. The number of executors on a node is limited by the number of cores of that node. A task is a unit of work that will be sent to one executor. A job is a parallel computation consisting of multiple tasks that gets spawned in response to a Spark action such as reduce. Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce).Tuesday, January 6, 2015
Two interesting crypto papers
An enciphering scheme based on a card shuffle
Efficient identity-based encryption without random oracles
B Waters - Advances in Cryptology–EUROCRYPT 2005, 2005 - Springer
Subscribe to:
Posts (Atom)